
Back in 2023 and 2024, the primary interaction model for generative AI was conversational retrieval where users asked questions and models provided text answers. Today in 2026, the landscape is defined by agency. We are no longer building passive tools that wait for input, instead building software entities capable of reasoning, planning, executing tools, and managing multi-step workflows to achieve high-level goals. This transition has introduced a layer of complexity that traditional API integrations cannot handle.
An agent tasked with “auditing quarterly financial reports” does not just make one call to a language model. It might need to query a vector database, reason about the results, call an external weather API, write a Python script to analyze the data, and then generate a final report. This “loop” or “chain of thought” requires multiple inference calls - but what happens when different AI models exist that are specialized for different tasks, and are operated at different price points? Which should you rely on?
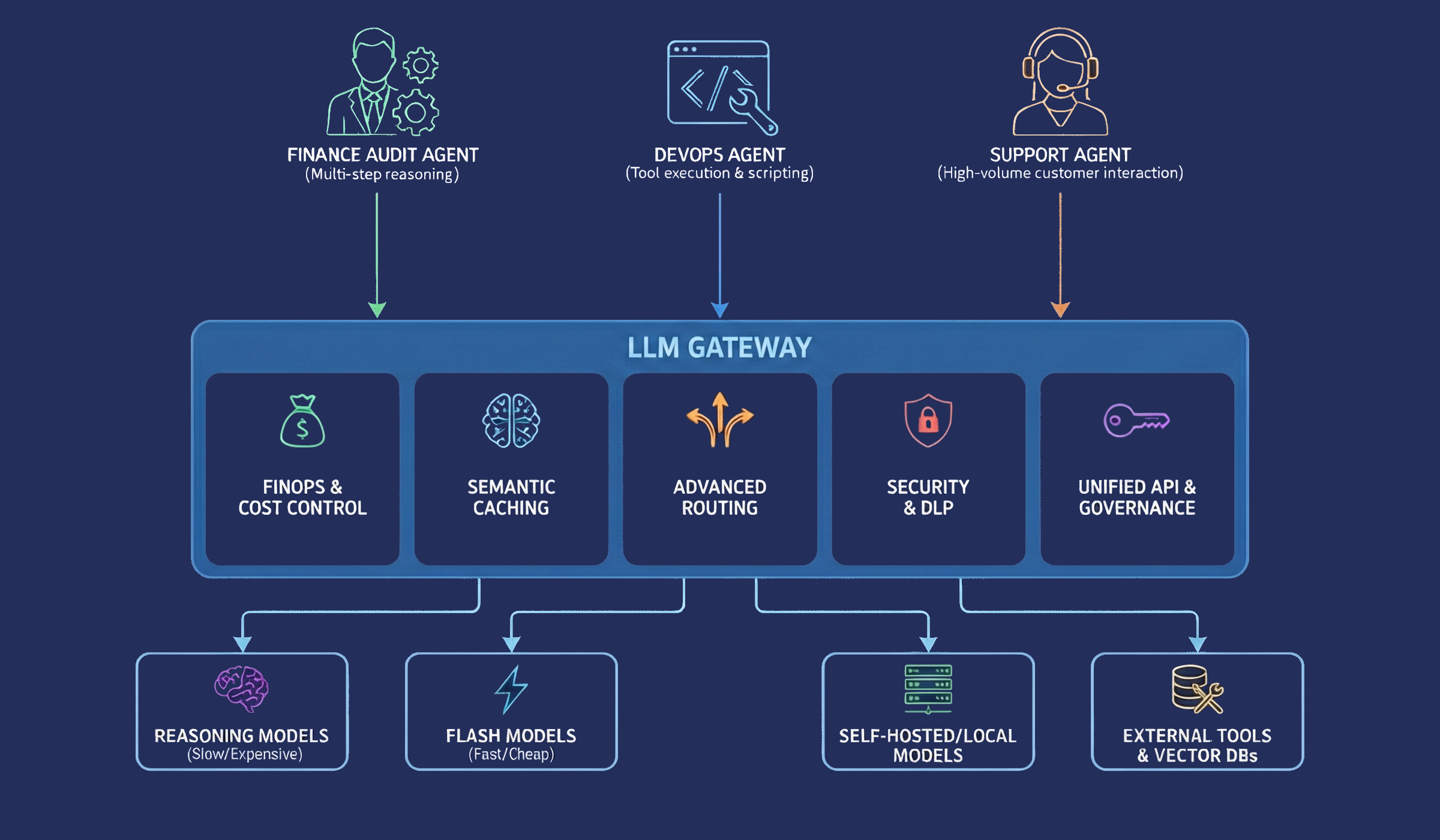
Enter the LLM Gateway. This specialized middleware layer is rapidly becoming the single most essential component of the modern AI stack. As organizations deploy agents that can modify databases, execute financial transactions, and interact with customers without human intervention, the risks of hallucinations, latency spikes, and cost overruns have compounded exponentially - and the gateway provides the necessary abstraction to manage these risks by offering a unified interface for routing, security, observability, and cost control.
Defining the LLM Gateway
Simply defined, an LLM gateway is a middleware component designed specifically for the unique traffic patterns of generative AI. It typically sits at the edge of an organization’s network or application environment, where it intercepts every request made by an internal agent to an external model provider or an internal self-hosted model, either via a reverse-proxy or by configuring the agent’s LLM API endpoint to point at the gateway.
One of the primary value propositions of a gateway to a developer is the Unified API, enabling developers to swap backend models by changing a single line of configuration in the gateway rather than rewriting application code. When an application sends a query, the gateway acts as the first point of contact. It parses the input, validates it for completeness and compliance, and prepares it for processing. This ensures the system handles only valid and secure data before it ever reaches the expensive model inference layer.
Cost Monitoring and Optimization
Every action an agent takes consumes tokens, and with complex agents running continuous loops, costs can spiral unpredictably. A “runaway agent” that gets stuck in a loop of error corrections can burn through a monthly budget in hours. LLM gateways provide the Financial Operations (FinOps) layer for AI that offers granular visibility into spend that provider dashboards cannot match.
The most effective way to reduce cost and latency is to not call the LLM at all. Semantic Caching is a powerful feature of advanced gateways. Unlike traditional caching which looks for exact text matches, semantic caching uses embedding models to understand the meaning of a request. If a user asks “What is the capital of France?” and the model answers “Paris,” the gateway stores this pair. If another user later asks “Tell me the capital city of France,” a semantic cache recognizes that the intent is identical and returns the stored response immediately.
This can have profound implications for agents, as they commonly perform redundant steps such as summarizing the same document multiple times or asking clarifying questions that have been asked before. Semantic caching can reduce token volume by 20% to 50% in many agentic workflows which results in direct cost savings and instant responses.
Advanced Model Request Routing
In 2026, no single model is the best at everything. Reasoning models excel at complex logic but are slow and expensive while flash models are fast and cheap but prone to hallucination. An effective agent needs to use the right tool for the job. Hard-coding these choices into the agent’s logic makes the system brittle and difficult to update. LLM gateways enable dynamic routing where the decision of which model to use is decoupled from the application code.
This routing can be configured via policies in the gateway. For example, a quality-first route might direct all requests to a high-reasoning model like GPT-5. If that model experiences high latency, the gateway could automatically downgrade to a faster model to maintain responsiveness. A cost-first route might use a cheaper model for requests classified as summarization tasks while reserving the expensive models for generation tasks. This allows for A/B testing different models in production without deploying new code.
For enterprise agents serving thousands of users, a single API key or provider account often has strict rate limits. Exceeding these limits results in throttling errors that crash agent workflows. LLM gateways mitigate this through load balancing. A gateway can be configured with multiple API keys for the same provider or keys for equivalent models across different regions.
Security and Observability
As AI becomes democratized, employees are increasingly spinning up their own agents to help with work. This creates a “Shadow AI” problem where sensitive corporate data is sent to external model providers without IT oversight. Gateways solve this by acting as the single egress point for all LLM traffic. By blocking direct access to provider APIs at the network firewall level and forcing all traffic through the gateway, organizations can gain complete visibility into what data is leaving the perimeter.
This centralization enables Data Loss Prevention (DLP) via LLM Observability. The gateway can be configured with regex patterns or specialized PII-detection models to scan every prompt for social security numbers, credit card details, or proprietary code markers. If sensitive data is detected, the gateway can either block the request or redact the sensitive tokens before sending the prompt to the external provider.
Gateway Best Practices for Agent Developers
To close, here are five essential gateway configurations for stabilizing your agent infrastructure.
1. Virtualize Your API Keys
Never allow an agent to use a raw provider key. Instead, provision “virtual keys” within your gateway for every distinct agent instance. This abstraction allows you to rotate the underlying provider credentials without redeploying your agent code. More importantly, it lets you set strict budget caps (e.g., $10/day) on a per-agent basis to prevent a runaway loop from draining your primary account.
2. Configure Token-Aware Rate Limiting
Traditional request-based rate limiting (e.g., 10 requests/minute) is dangerous for agents because one request might consume 50 tokens while another consumes 10,000. Configure your gateway to enforce “Token Bucket” rate limits. This ensures that a high-throughput agent is throttled based on the actual compute volume it consumes rather than just the number of API calls it makes.
3. Enable Semantic Caching for Loops
Agents often repeat similar reasoning steps or redundant queries. Enable semantic caching at the gateway level to intercept these repetitive calls. By serving a cached response for a recurring “thought” or search query, you reduce latency to near-zero for that step and eliminate the cost entirely.
4. Implement Gateway-Level Circuit Breakers
Do not rely on your agent’s code to handle provider outages properly. Instead, configure circuit breakers on your gateway to monitor error rates from upstream providers. If a provider fails (e.g., 5 times in 10 seconds) the gateway can automatically “trip” the circuit and reject traffic or route it to a fallback model immediately. This prevents your agent from hanging and preserves system stability.
5. Intercept Sensitive Tool Calls
Use your gateway as a security checkpoint for tool use. Configure policies to inspect the payload of outgoing API calls your agent makes, and if the gateway detects a call to a sensitive endpoint (like DELETE /database), it can automatically block the request or route it to a “Human-in-the-Loop” approval queue.
Closing Thoughts
LLM gateways are the invisible backbone that allows governance to function as a control layer for AI agents, and turn autonomous behavior into something measurable, enforceable, and scalable. Without this layer, agentic systems remain powerful but can be ungovernable. With it, enterprises gain the foundation required to move from experimentation to production-grade AI in 2026 and beyond.